Cách mà người ta huấn luyện LLM?
Một cách ngắn gọn nhất, mục tiêu của hầu hết các đơn vị phát triển LLM hiện nay là nhồi càng nhiều kiến thức càng tốt cho nó. Bằng cách tìm mọi nguồn dữ liệu, người ta sẽ "băm" các thông tin đó ra và lưu trữ dưới dạng các vector, mỗi vector là một chuỗi các số và lưu trong một cơ sở dữ liệu vector. Chúng ta hay nghe nói model A có 9 tỷ tham số, model B có 90 tỷ tham số, thì nó chính là từ đây mà ra.
Quá trình train một model sẽ chia ra thành 2 giai đoạn đó là:
- pre-training
- fine-tuning
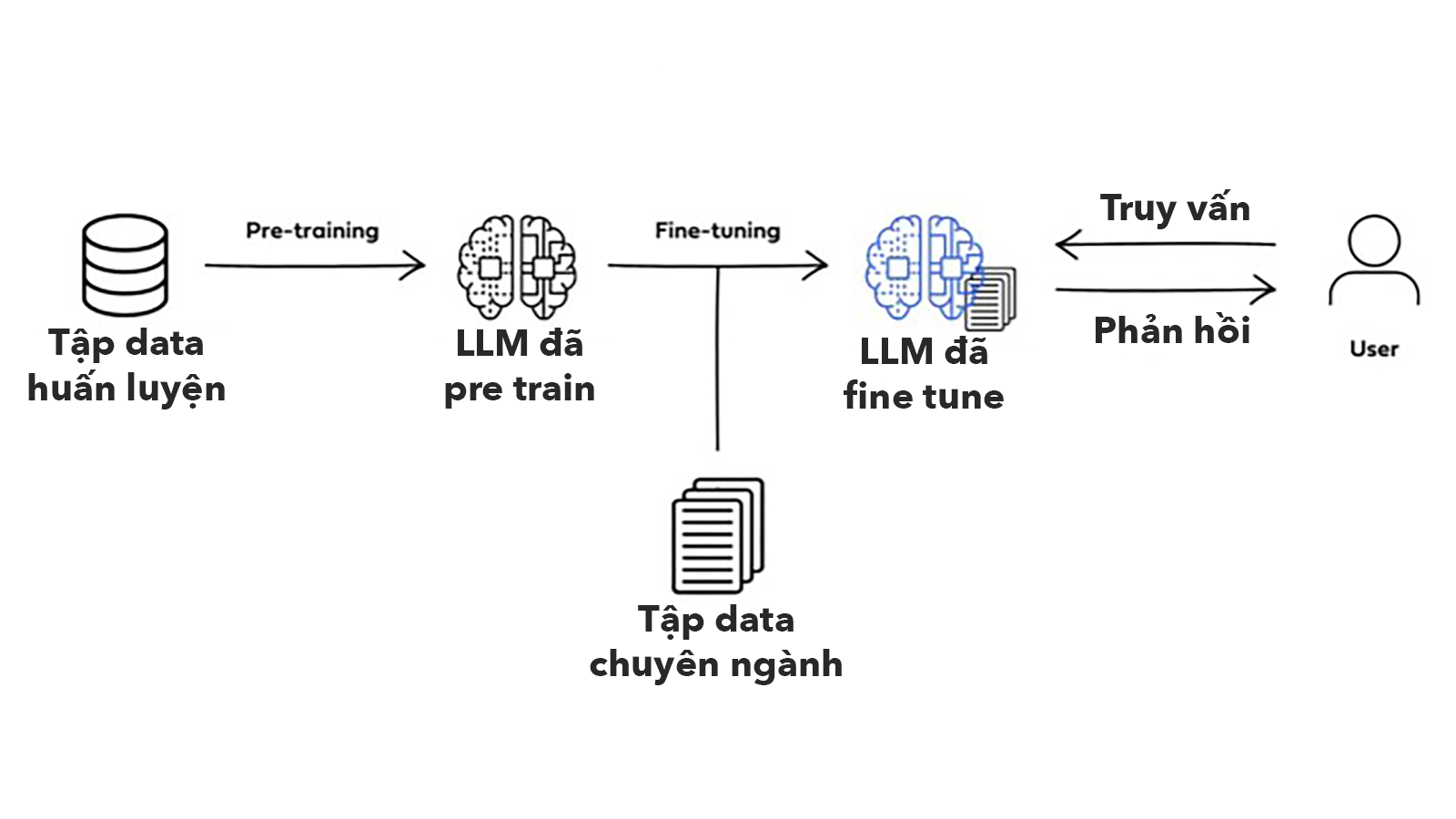
Tìm hiểu giai đọn pre-training
Ở giai đoạn này, LLM sẽ được cho tiếp xúc với lượng khổng lồ các văn bản từ sách, các bài viết, trang web, những video / ghi âm được trích lời ra và chuyển thành text,... Việc này giống như đi vào một thư viện thế giới và đọc hết sách trong đó vậy. Tất nhiên vì nó là máy nên nó đọc nhanh hơn con người rất nhiều.
Sau khi review toàn bộ văn bản, LLM sao bắt đầu xác định cấu trúc của ngôn ngữ trong những văn bản đó (xác định pattern - mô hình). Kết quả của quá trình này, LLM sẽ có thể hiểu được
- Trong một ngôn ngữ, các từ nào thường sẽ đi chung với nhau (thí dụ như Chó thì thường sẽ có liên quan tới sủa, cún con,...)
- Cấu trúc câu và ngữ pháp trong mỗi ngôn ngữ khác nhau (thí dụ như cấu trúc chủ ngữ vị ngữ, vị trí của động từ, danh từ,...)
- Một từ cụ thể sẽ liên quan tới các chủ đề nào (hiểu được chó và cún đều có liên quan tới thú cưng, động vật, huấn luyện,...)
Sâu hơn một chút về quá trình xử lý đống text này của LLM. Đầu tiên, toàn bộ text sẽ được "băm" ra thành những "mảnh". Thí dụ như một câu sẽ được băm ra thành những phần nhỏ gọi là các tokens. Mỗi tokens này có thể là một từ hoặc một phần của một từ hoặc một ký tự đặc biệt nào đó (thí dụ dấu chấm than, chấm hỏi,...) Sau khi băm, LLM sẽ lưu các token này dưới dạng vector. Hoạt động này được gọi là embedding hay encoding. Tất cả các vector này sẽ được lưu trữ trong một không gian database vector (anh em cứ hình dung nó như một cái nhà kho).
Bản chất, các vector này chính là một cách biểu diễn toán học của token đó. Thí dụ như chữ "chó" sẽ được biểu diễn dưới dạng [0.51, 97, 23, 45.99,....]. Nói cách khác, thay vì lưu dưới dạng text như chúng ta đang đọc, thì bây giờ nó được "dịch" sang vector chứa các số thực để máy nó cũng đọc được giống như chúng ta. Chúng ta đi học thì sẽ biết đọc, máy tính thì nó dùng các hàm số, thuật toán để "đọc".
Sau khi Embedding, LLM sẽ "hiểu" được ý nghỉa của từng token dựa trên những pattern mà nó đã học trước đó. Do mỗi token đều được đại diện bằng các con số trong chuỗi số chưa trong vector, nên người ta sẽ có các phép toán để đo lường "độ gần nhau" của các vector, đại khái vậy là các mà LLM hiểu được ý nghĩa của các vector. Từ đó, những vector của các token có "nghĩa" tương tự nhau, cùng một nhóm chủ đề,... sẽ được "sắp xếp" ở gần nhau trong không gian vector.
Tìm hiểu giai đoạn fine-tuning
Sau giai đoạn Pre Training, LLM sẽ được chuyển sang giai đoạn Fine tuning - tinh chỉnh. Tới đây, LLM sẽ được đào tạo bổ sung bằng các bộ dữ liệu nhỏ hơn có liên quan tới các tác vụ cụ thể. Anh em cứ hình dung là giai đoạn đầu LLM sẽ học hết lớp 12, tới giai đoạn này thì nó vào đại học học chuyên ngành.
Cụ thể, trong giai đoạn Fine tuning, LLM sẽ được cho chạy thử những task cụ thể để tạo ra kết quả dựa trên những dữ liệu mẫu đã được gắn nhãn. Các dữ liệu mẫu này đã được gắn nhãn, chia thành những chỉ mục, được diễn tả sẵn nội dung. Nôm na thì ở đây, người ta sẽ cho model biết đầu ra là cái gì và yêu cầu nó chạy sao cho ra như vậy thì mới đúng.
Việc pre training và fine tuning đều nhằm dạy cho LLM nhận biết được pattern của dữ liệu. Sau này, khi gặp một câu lệnh, nó sẽ dựa vào pattern đã học được để hiểu câu lệnh này, sau đó tạo ra câu trả lời tương ứng. Tới đây thì chúng ta có thể thấy, mặc dù model AI không thực sự hiểu ngôn ngữ con người, nhưng bằng cách dạy cho nó "ngôn ngữ đã được chuyển về số", model sẽ có thể xác định được pattern, từ đó bắt chước được phản ứng ngôn ngữ của con người.
Trên đây chính là cách mà một LLM học và xử lý ngôn ngữ con người. Nó không chỉ có thể áp dụng trong chatbot vấn đáp, mà còn có thể phân tích được tình cảm, nhận diện chủ đề, phân loại tài liệu,... tất cả đều dựa trên thuật toán xác định mức độ liên quan của các vector đại diện cho từ, cụm từ,...









